Suggested Articles

Checking Under the Dashboard: Gender Bias in Data and Tech
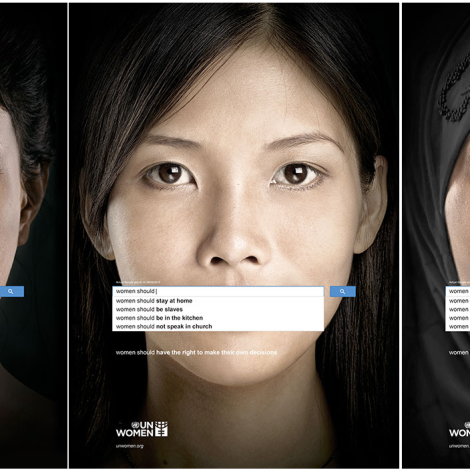
This article reveals the often-overlooked consequences of excluding women’s voices from the development of technology. The result is harming women now and in future generations. Global development practitioners,...